Deep RL Agents: DQN and PPO for Strategic Play
Highlights
- Implements DQN with experience replay and a target network, and PPO with clipped surrogate objective and GAE, both from scratch.
- Trains agents on Connect Four through self-play, tracking win rates and training stability across thousands of episodes.
- Grounds the implementation in policy-gradient derivations covering Bellman equations, advantage functions, and the PPO clipping bound.
Foundations
The project starts from first principles: value functions, the Bellman optimality equation, temporal difference learning, policy gradient derivations, and advantage estimation. Every design choice in the code traces back to a derivation: why experience replay breaks correlation, why a target network prevents the bootstrap from chasing a moving target, and why the PPO clipping bound keeps policy updates conservative.
Shared network architecture
Both agents use a hybrid CNN+ViT backbone to encode the Connect Four board state. A convolutional front-end scans the 6x7 grid for local threat patterns, detecting horizontal, vertical, and diagonal threat sequences across the immediate neighborhood of each cell. Its feature maps are then passed to a Vision Transformer that attends globally across all board positions, letting the network weigh distant threats and strategic configurations that a convolutional layer alone would miss. From there, DQN branches into separate advantage and value streams (dueling architecture), while PPO branches into a policy head and a value head. Holding the backbone fixed across both algorithms made the comparison clean: any performance difference comes from the learning rule, not from how the board was encoded.
DQN
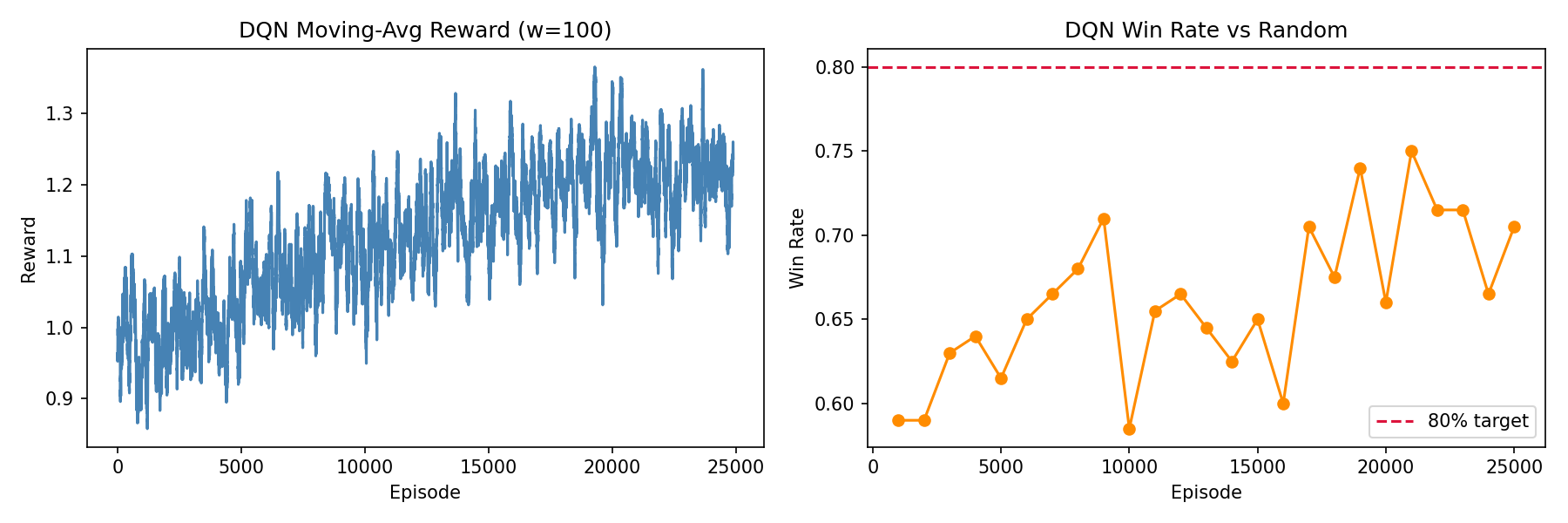
The DQN agent uses Q-value approximation with a replay buffer to break sample correlation and a target network to stabilize the bootstrap. On Connect Four, it learns to block forced wins and set up threats. Training curves show steady win-rate gains early, followed by a plateau as the agent exhausts easy gains from obvious defensive play, with Q-value instabilities visible in episodes before the target network sync.
PPO
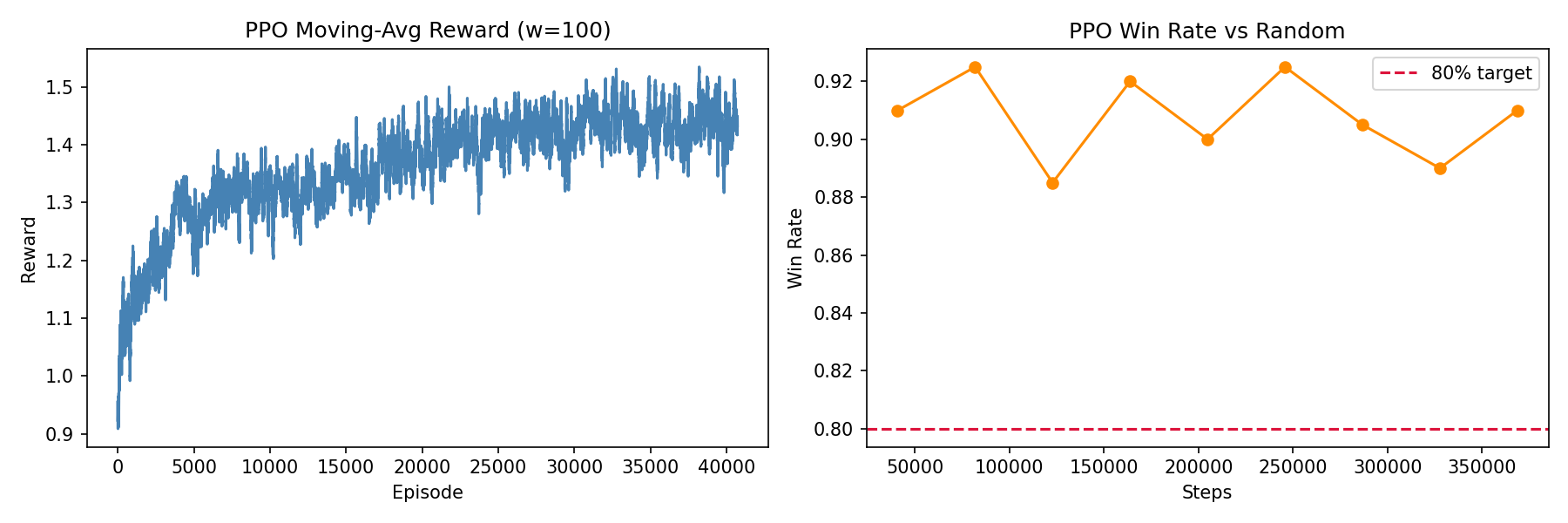
PPO uses the clipped surrogate objective to limit destructive updates and generalized advantage estimation for lower-variance returns. It trains on-policy, which means no replay buffer and tighter feedback between experience and gradient updates. On Connect Four, PPO reached a higher peak win rate than DQN and showed more consistent late-game strategic play, though it was slower to start learning in the early episodes.
Comparison
The head-to-head comparison showed complementary strengths: DQN learned faster initially due to off-policy sample reuse, but PPO converged to better final performance with more stable training dynamics. The key difference was in how each algorithm handles the long-horizon credit assignment problem in Connect Four, where winning or losing a game depends on a sequence of moves rather than any single action.
Self-play
Both agents were trained entirely through self-play: each agent played against a copy of itself (or a recent checkpoint) rather than a fixed opponent. This matters because a fixed opponent creates a stationary target that the agent can overfit to without developing general strategy. With self-play, the opponent difficulty scales automatically as the agent improves -- the agent is always playing against a version of itself that is roughly as good as it currently is. In practice this means the training distribution is always on the frontier of the agent's current ability, which forces genuine strategic learning rather than memorization of a fixed opponent's weaknesses.
MCTS planning
A stronger AlphaZero-style agent was developed alongside DQN and PPO, combining Monte Carlo Tree Search (MCTS) with a learned policy and value network. Where DQN and PPO act in a single forward pass, the MCTS agent builds a search tree at each move: it simulates many possible continuations, using the policy network to focus search toward promising lines and the value network to estimate outcomes without playing to completion. The result is a qualitatively different kind of intelligence -- it can look several moves ahead and reason about forced sequences in a way that reactive one-step policies cannot. This agent served as the final benchmark opponent, and its strength made clear how much headroom remains between learning a good reactive policy and actually planning.
Game replay
A recorded self-play game between the trained DQN and PPO agents. DQN (accent) builds a horizontal threat across the third row while PPO (amber) focuses on the center column. DQN spots the win and completes the four-in-a-row.
Training curves